In this post I would like to write on how to succeed in a technical interview based on my experience as an interviewer. Most of the interviews follows some patterns. If you understand it and frame your response in the same way you can clear any interview. If you don't know stuff this might not help you, but if you are prepared, this article will help you show of your full potential.
If you are skillful the only reason you can loose an interview is by lack of preparation. You may know all the stuff but you still needs to prepare by reading books, article etc.. Theses may not teach you anything new but will help in organizing things that you already know. Once you have organized information it is really easy to access it. You should read not only for interviews, make it a practice and get better at your job.
Most of the time interviewer is looking for a candidate who can work with him. The vacancy may be in other teams but they use this parameter to judge. Mostly this article contains general tips. These are targeted for 2 to 6 years experienced candidates.
1. Be honest and don't bluff
Answer what you know, confidently. If you have been asked a question that you don't know, Start by telling "I am not sure, but I think It is .....". Never tell a wrong answer confidently. That will make them doubt your correct answers also or may feel that they were guesses. You can't use this technique for every question, but I would think 25% is a good amount. Most importantly this shows your ability to think and a never die attitude. No one wants to work with people says "I can't do this". Try to do some thing about all the questions.
2. Be ready to write Code
If you are been asked to write some code, be careful and follow some basic standards. I heard people telling me "I forgot the syntax..." and this for the syntax of a for loop. No one expect you to remember everything but basics like looping, if conditions, main method, exceptions are never to be forgotten. If you did, brush them up. Always write the code with good indentation using lots of white spaces. That might make up for your bad handwriting!!
3. Get ready to explain about your project
As engineers you have to understand the business before you start code it. So you should be able to explain what is being done in your project. Write down 3-4 lines that will explain the project in high level. By hearing the lines some one out side your team should get an idea about it. Because we always works inside on features, most of the time it is difficult to frame these. Check your client's internal communications how they are marketing and get some clue from it. Practice what your are going to say with friends make make sure you are on to the point.
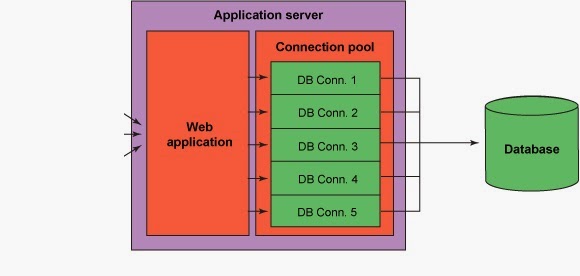
Once you have explained about the business needs then you will be asked about the technical architecture of the project. You have to be prepared with a architecture diagram that shows how the interaction of components in your project. It don't have to be in any specific UML format, but make sure you can explain stuff relating to the diagram you have drawn. For example if you are working in a web application show how the data is flow from UI to DB. You can show different layers involved, technologies used etc.. The most important part is you should be clear in your mind about what you are currently working on.
4. Convert arguments to conversation
Even if you know that that person is wrong do not argue and try to continue the conversation saying "Ok, But I am not so sure if that is correct, I will check that out". This keeps the person in good terms. Be an active listener during the interview use reference to your experience when you are answering.
5. Be prepared for the WHY question
Good interviews focus on the question "Why?". It might start with "What" but will end in "Why?". For example in Java typical question would be "What is the difference between String and StringBuffer?". A follow-up why question will be like "Why is String has so-and-so" or "How is it done..?". Be ready to give inside information by answering "How?" and "Why" parts of he question.
6. Tell about your best achievement
During your work there might be something that you consider as your best achievement. It is important to describe it in such a way that interviewer feels that you have did something extraordinary there. So, prepare a believable story on how your abilities helped you complete that task. It is important to prepare this because it takes time to dig your memory and find situations.
7. Do you have any questions for me?
This question gets repeated in every single interview. Here you don't actually care about the answers; but you should make yourselves look good by asking "smart" questions. This article will help you in this.